
This week we are going to learn how to manipulate, compute, and check the reliability of your variables. You will learn how to re-code the response of your variables and compute to a new variable of your interest.
RE-CODING
Why re-coding?
There are a few reasons why you need to re-code your variables. First of all if your variable is unreasonably skewed or is not normally distributed and you want to make the response to that variable less skewed so that your results would be enhanced based on proportional response to your variable. For example, let's take a look at this variable--number of absence-- in this dataset (file name: studentdata2008). Students responded to this variable by writing down their total number of absences since the beginning of their current academic year. The response ranges from 0 to more than one times. You would do the command tab to get the detail list of each response of "absent" variable. Here is how it looks like:
tab absent
 As you can see from the above table, only very few students were absent more than 6 times. So your data were skewed toward 0-5 times. When you look at the Skewness value of this variable, it's 2.49 and Kurtosis it's 11.15 which indicate highly skewed (see the short and sweet description of Skewness and Kurtosis here for more information). In this case, you would re-code this variable by combining those who were absent more than 6 times into one group, calling it as "more than 6 times". You leave 0-5 as it it--don't touch them. To recode this variable, use this command: recode absent (0=0)(1=1)(2=2)(3=3)(4=4)(5=5)(6/25=6). Here is how it looks like:
As you can see from the above table, only very few students were absent more than 6 times. So your data were skewed toward 0-5 times. When you look at the Skewness value of this variable, it's 2.49 and Kurtosis it's 11.15 which indicate highly skewed (see the short and sweet description of Skewness and Kurtosis here for more information). In this case, you would re-code this variable by combining those who were absent more than 6 times into one group, calling it as "more than 6 times". You leave 0-5 as it it--don't touch them. To recode this variable, use this command: recode absent (0=0)(1=1)(2=2)(3=3)(4=4)(5=5)(6/25=6). Here is how it looks like:
recode absent (0=0)(1=1)(2=2)(3=3)(4=4)(5=5)(6/25=6)
 That is what you get based on that recode command above. Next, tab absent again, and you will see that the response 6-25 was combined. here is how it looks like:
That is what you get based on that recode command above. Next, tab absent again, and you will see that the response 6-25 was combined. here is how it looks like:
tab absent
 Now your variable absent looks like it's normally distributed. The Skewness was reduced to 0.57 and Kurtosis to 1.88. The rule of thumb of a normally distributed variable would be a skewness of 1 and lower (nearer to zero is better) and Kurtosis of lower than 3.
Now your variable absent looks like it's normally distributed. The Skewness was reduced to 0.57 and Kurtosis to 1.88. The rule of thumb of a normally distributed variable would be a skewness of 1 and lower (nearer to zero is better) and Kurtosis of lower than 3.
So how did you do to get the values of Skewness and Kurtosis of the absent variable?
Type command summary (or sum) of absent variable by requesting detail (or simply d for shortcut). Here is how it looks like:
sum absent, detail

So there you have the values of Skewness and Kurtosis. The values indicate that your variable absent looks normally distributed. Below is a screenshot of how Skewness and Kurtosis are mentioned in a journal article (click here for the full article in the American Journal on Addictions):

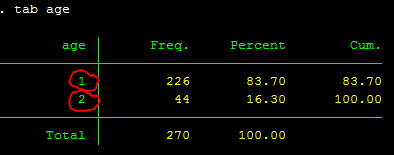
Another reason for you to recode a variable is when you want to group the response into a category. Again, this is purpose driven--very subjective. Now look at the variable "age". Ages of respondents range from 10-19 years old. If your purpose is to group them into a 5-year range, then you will have two groups: 10-14 and 15-19. You would follow the same as the above procedures. Here is how it looks like when you tab age:
tab age

Now let's do recoding of age:
recode age (10/14=1)(15/19=2)
or
recode age (min/14=1) (15/max=2)
I would recommend you to label this age variable as its values have been recoded so that you can still remember when you come back to the data in the future. Use the command: label var age "5-year range of age, 1=10-14 and 2=15-19"; description inside the quotation mark can be anything you want to call. It's for you to remember what it is you recoded. Here is how it looks like after you label it:
label var age "5-year range of age, 1=10-14 and 2=15-19"
tab age

There is another way to label values (1 or 2 for the age above) and have it displayed in the output table like this one above. So instead of showing 1 and 2 and look at the label of the variable in the red circle, you can have it shown 10-14 or 15-19 instead. Here is how you do it:
label define age1 1 10_14yrs 2 15_19yrs
label values age age1

The "age1" can be anything you want to call it, and have need something for you to define the value label. Another important thing to remember is that please be careful about the "hyphenate" and "dash" as Stata is sensitive to the hyphenate one. Stata would treat it as "from this to that." So if it is a label you want to remember on your own, use "dash". For the example above, if you write "10-14yrs, then Stata would not be running, and it shows an error message saying that it's "invalid syntax."
GENERATING NEW VARIABLES
You always want to retain your original variables before you recode because there is a chance that you may want to come back to those variables again. You never know. If you do not generate a new one, then after you recode it, you can never recall it back. I recommend that you always generate a new variable that is equal to the one you want to work on. A good example would be the variables that we used above: absent and age. You always want to retain these variables and recode the ones that you generate for current use. Generating a variable can be done easily with the command: generate or gen for short. Now let's look at the variables absent again and generate a new one of it. A new variable that you generated (or created) can be called anything you would like to (but no spacing). I myself prefer to use rc adding to the new variable being generated so that I know that it is recoded. So for the absent variable, the newly generated one would be called "absent_rc". So here is how it looks like:
gen absent_rc = absent

And again, you should label this variable so that you won't forget what it is called when you come back later. I assume that by now you know how to label your variables. So show me how you would do it!. After you have done it, the new label will appear in the yellow highlight part above. Please note that when you generate a new variable that is equivalent to your old one, the new one must be placed first, right after "gen" command. Remember, you generate new variable to be equal to the old one, if that helps you memorize.
Now that you have generate your new absent variable, you can use that one to do the recoding. Simple!
--------
Command "gen" can be used to generate (or convert) values of your variables as well. For example, for your variable "dob" (date of birth in actual year), the response was in actual year. It looks like this by using tab command:

... but you want to make this variable to actual age (let's say in 2014, how old your participants are). First of you need to call this new variable that you want to generate into actual age. It is up to you what to call, but I would call it as "dob_age". You can generate dob into year by using this one straight command: gen dob_age=(2014 - dob). [Note: it's 2014 minus dob]:
gen dob_age=(2014 - dob)

Now your dob variable has been converted into actual age, instead of year.
Let's keep it simple for now about the use of gen command. There are many more functions that gen command can give you. For more information on gen, the UCLA website is useful (here is the link).
COMPUTE NEW VARIABLES
Computation to a new variable can be done when you have several variables that you want to average them to a single variable. For example, in your Happiness Survey data (access to the data here), there are 8 variables that were used to measure physical problems of the participants. So by combining or averaging the 8 variables together, you create a new single variable or a scale that measures physical problem. You use command "gen" or "egen" to average these 8 variables: gen physical_problem = (Psleep + Pache + Phead + Peat + Ptired + Pfam + Pworry + Pfocus)/8. Here is how it looks like:
gen physical_problem = (Psleep + Pache + Phead + Peat + Ptired + Pfam + Pworry + Pfocus)/8

Now you have created/computed/generated a new variable or a new measure for physical health. And again, you should label this variable so that you won't forget what it is later. I assume that by now you know how to label your variable.
Another way to generate this physical problem variable, you can use "egen" command. It looks like this:
egen physical_problem = rmean (Psleep - Pfocus)
That should also generate/compute your physical problem measure.
RELIABILITY CHECK
Before you create a measure such as the one above, the physical problem one, you may want to check how reliable the measure is. In other words, how each item is correlated with one another. This is called inter-item reliability. We use Cronbach's alpha to evaluate the reliability of a measure you are trying to create. As a rule of thumb, a Cronbach's alpha of above 0.70 is considered a good and 0.80 up is considered to be highly reliable. Let's look at the physical problem measure and how reliable it is. We can use the command: alpha. Here is how it looks like:
alpha Psleep - Pfocus

What it shows here is the alpha = 0.7772 (or .78). We can say that the physical problem measure is reliable. A value below .70 is usually not so welcomed by peer-reviewed journal.
This is an example of how this part of analysis is presented in a peer-reviewed journal.

Source: Plunkett, S. W., Henry, C. S., Robinson, L. C., Behnke, A., & Falcon III, P. C. (2007). Adolescent perceptions of parental behaviors, adolescent self-esteem, and adolescent depressed mood. Journal of Child and Family Studies, 16(6), 760-772.
PRACTICE IN CLASS
Now let's practice this in class as part of our class activities. Use this data for this purpose.
We will use the variables gpa, absent, and age1skol to answer the following questions:
1. Do students who have 3 times and above of absence tend to start their first grade later than those who have the number of absence of 2 times and below (hint: group absent into two groups)?
2. Do students who have GPA of above average (5 and above) tend to start their first grade earlier than those who have a GPA of lower than the average (below 5)?
3. Make sure that after you group the responses, you label the newly created variables so that you remember what they are.
PRACTICE ON YOUR OWN
Using studentdata2008 and do the following:
Good luck!
RE-CODING
Why re-coding?
There are a few reasons why you need to re-code your variables. First of all if your variable is unreasonably skewed or is not normally distributed and you want to make the response to that variable less skewed so that your results would be enhanced based on proportional response to your variable. For example, let's take a look at this variable--number of absence-- in this dataset (file name: studentdata2008). Students responded to this variable by writing down their total number of absences since the beginning of their current academic year. The response ranges from 0 to more than one times. You would do the command tab to get the detail list of each response of "absent" variable. Here is how it looks like:
tab absent
recode absent (0=0)(1=1)(2=2)(3=3)(4=4)(5=5)(6/25=6)
tab absent
So how did you do to get the values of Skewness and Kurtosis of the absent variable?
Type command summary (or sum) of absent variable by requesting detail (or simply d for shortcut). Here is how it looks like:
sum absent, detail
So there you have the values of Skewness and Kurtosis. The values indicate that your variable absent looks normally distributed. Below is a screenshot of how Skewness and Kurtosis are mentioned in a journal article (click here for the full article in the American Journal on Addictions):
Another reason for you to recode a variable is when you want to group the response into a category. Again, this is purpose driven--very subjective. Now look at the variable "age". Ages of respondents range from 10-19 years old. If your purpose is to group them into a 5-year range, then you will have two groups: 10-14 and 15-19. You would follow the same as the above procedures. Here is how it looks like when you tab age:
tab age
Now let's do recoding of age:
recode age (10/14=1)(15/19=2)
or
recode age (min/14=1) (15/max=2)
I would recommend you to label this age variable as its values have been recoded so that you can still remember when you come back to the data in the future. Use the command: label var age "5-year range of age, 1=10-14 and 2=15-19"; description inside the quotation mark can be anything you want to call. It's for you to remember what it is you recoded. Here is how it looks like after you label it:
label var age "5-year range of age, 1=10-14 and 2=15-19"
tab age
There is another way to label values (1 or 2 for the age above) and have it displayed in the output table like this one above. So instead of showing 1 and 2 and look at the label of the variable in the red circle, you can have it shown 10-14 or 15-19 instead. Here is how you do it:
label define age1 1 10_14yrs 2 15_19yrs
label values age age1
The "age1" can be anything you want to call it, and have need something for you to define the value label. Another important thing to remember is that please be careful about the "hyphenate" and "dash" as Stata is sensitive to the hyphenate one. Stata would treat it as "from this to that." So if it is a label you want to remember on your own, use "dash". For the example above, if you write "10-14yrs, then Stata would not be running, and it shows an error message saying that it's "invalid syntax."
GENERATING NEW VARIABLES
You always want to retain your original variables before you recode because there is a chance that you may want to come back to those variables again. You never know. If you do not generate a new one, then after you recode it, you can never recall it back. I recommend that you always generate a new variable that is equal to the one you want to work on. A good example would be the variables that we used above: absent and age. You always want to retain these variables and recode the ones that you generate for current use. Generating a variable can be done easily with the command: generate or gen for short. Now let's look at the variables absent again and generate a new one of it. A new variable that you generated (or created) can be called anything you would like to (but no spacing). I myself prefer to use rc adding to the new variable being generated so that I know that it is recoded. So for the absent variable, the newly generated one would be called "absent_rc". So here is how it looks like:
gen absent_rc = absent
And again, you should label this variable so that you won't forget what it is called when you come back later. I assume that by now you know how to label your variables. So show me how you would do it!. After you have done it, the new label will appear in the yellow highlight part above. Please note that when you generate a new variable that is equivalent to your old one, the new one must be placed first, right after "gen" command. Remember, you generate new variable to be equal to the old one, if that helps you memorize.
Now that you have generate your new absent variable, you can use that one to do the recoding. Simple!
--------
Command "gen" can be used to generate (or convert) values of your variables as well. For example, for your variable "dob" (date of birth in actual year), the response was in actual year. It looks like this by using tab command:
... but you want to make this variable to actual age (let's say in 2014, how old your participants are). First of you need to call this new variable that you want to generate into actual age. It is up to you what to call, but I would call it as "dob_age". You can generate dob into year by using this one straight command: gen dob_age=(2014 - dob). [Note: it's 2014 minus dob]:
gen dob_age=(2014 - dob)
Now your dob variable has been converted into actual age, instead of year.
Let's keep it simple for now about the use of gen command. There are many more functions that gen command can give you. For more information on gen, the UCLA website is useful (here is the link).
COMPUTE NEW VARIABLES
Computation to a new variable can be done when you have several variables that you want to average them to a single variable. For example, in your Happiness Survey data (access to the data here), there are 8 variables that were used to measure physical problems of the participants. So by combining or averaging the 8 variables together, you create a new single variable or a scale that measures physical problem. You use command "gen" or "egen" to average these 8 variables: gen physical_problem = (Psleep + Pache + Phead + Peat + Ptired + Pfam + Pworry + Pfocus)/8. Here is how it looks like:
gen physical_problem = (Psleep + Pache + Phead + Peat + Ptired + Pfam + Pworry + Pfocus)/8
Now you have created/computed/generated a new variable or a new measure for physical health. And again, you should label this variable so that you won't forget what it is later. I assume that by now you know how to label your variable.
Another way to generate this physical problem variable, you can use "egen" command. It looks like this:
egen physical_problem = rmean (Psleep - Pfocus)
That should also generate/compute your physical problem measure.
RELIABILITY CHECK
Before you create a measure such as the one above, the physical problem one, you may want to check how reliable the measure is. In other words, how each item is correlated with one another. This is called inter-item reliability. We use Cronbach's alpha to evaluate the reliability of a measure you are trying to create. As a rule of thumb, a Cronbach's alpha of above 0.70 is considered a good and 0.80 up is considered to be highly reliable. Let's look at the physical problem measure and how reliable it is. We can use the command: alpha. Here is how it looks like:
alpha Psleep - Pfocus
What it shows here is the alpha = 0.7772 (or .78). We can say that the physical problem measure is reliable. A value below .70 is usually not so welcomed by peer-reviewed journal.
This is an example of how this part of analysis is presented in a peer-reviewed journal.
Source: Plunkett, S. W., Henry, C. S., Robinson, L. C., Behnke, A., & Falcon III, P. C. (2007). Adolescent perceptions of parental behaviors, adolescent self-esteem, and adolescent depressed mood. Journal of Child and Family Studies, 16(6), 760-772.
PRACTICE IN CLASS
Now let's practice this in class as part of our class activities. Use this data for this purpose.
We will use the variables gpa, absent, and age1skol to answer the following questions:
1. Do students who have 3 times and above of absence tend to start their first grade later than those who have the number of absence of 2 times and below (hint: group absent into two groups)?
2. Do students who have GPA of above average (5 and above) tend to start their first grade earlier than those who have a GPA of lower than the average (below 5)?
3. Make sure that after you group the responses, you label the newly created variables so that you remember what they are.
PRACTICE ON YOUR OWN
Using studentdata2008 and do the following:
- Create a new variable of sexstud (and call it as gender)
- Label the values of your newly created variable gender. Your task is to change from 0 to female, and 1 to male (hint: use label define and label values commands).
- Currently, your gpa variable is a continuous variable (ranging from as low as 2.05-9.63).
- Your task is to create a new gpa variable into four groups,
- Then calculate percentages of the four groups.
- After that, please label to the values of the groups.
- Then, find out how each of these GPA groups is different by gender (e.g., who perform better? Male or Female?).
- Recode the variable numstud (e.g., number of students) into whatever number of group you think would makes sense practically in the real world.
- Then, recode variable absent (e.g., the number of absent) into whatever number of group you think makes sense practically.
- Label to the values of the groups of absence and the group of number of students.
- Your final task is to run a cross-tabulation between number of students and number of absent. Do those coming from a larger class size have more number of absence?
- Use, Happiness Survey, and create a measure called Happiness
- How reliable is this measure?
- Are men more likely to be reporting more happiness than women?
- Are those reporting higher level of happiness more likely to do well academically (e.g., using gpa variable)?
Good luck!
It is really lovely feelings when you win your first time while you placed your work. This page http://www.articlerewriteservice.net/the-best-article-rewriter-online/ will give you the best paragraph writing services we have.
ReplyDeleteNice explanation and article. Continue to write articles like these, and visit my website at https://usacrack.info/ for more information.
ReplyDeleteDAEMON Tools Pro Crack
iMazing Crack
Stata 17.0 Crack
HMA Pro VPN Crack
Enscape3D Sketchup Crack
Quillbot Premium Crack
EasyWorship Crack
EaseUS MobiSaver Crack
Teorex Inpaint 9.1 Crack
ReplyDeleteNice explanation and article. Continue to write articles like these, and visit my website at https://usacrack.info/ for more information.
SparkoCam Crack
Stata Crack
Nice explanation and article. Continue to write articles like these, and visit my website at https://usacrack.info/ for more information.
ReplyDeleteAirServer Crack
Express VPN Crack
Avast Cleanup Premium Crack
Windows 11 Crack
Stata Crack
I came here looking for advice and also discovered a platform that can help me do it too. Thanks
ReplyDeleteExpress Scribe Crack
iMyFone Fixppo Crack
Stata Crack
Nice article. Thanks for sharing.
ReplyDeleteArtificial Intelligence Courses Online
Artificial Intelligence Training in Hyderabad
Artificial Intelligence Online Training Institute
Artificial Intelligence Training
Artificial Intelligence Training in Ameerpet
Artificial Intelligence Course in Hyderabad
Artificial Intelligence Online Training
AI Training In Hyderabad
AI Online Training