This week we are going to talk about t-test. We use t-test to serve a few purposes but the two main things are comparing means of a continuous variable (e.g., GPA or income) with a categorical variable (e.g., gender or type of university--public vs. private)--that is called "independent group ttest," and comparing means between two continuous variables (e.g, pre-test and post-test)--that is called "paired t-test".
Independent Group T-Test
Research questions for this type of test may include: (1) are there any income differences between male and female employees? (2) Is GPA different by gender? (3) compared to those who have studied abroad, do those who have not earn more salary? (4) do people who went to a private university earn better salary compared to those who went to a public university? etc. Remember that t-test allows only two groups (e.g., male or female; study abroad vs. not study abroad). If you have a variable that has three or more groups (e.g., ethnicity or type of car etc.), then ANOVA (Oneway Analysis of Variance) is appropriate. We will cover this later. Let's look at our studentdata2008 data and try to run a few t-tests. First let's see if there is any difference in GPA between male and female students. The command for it is: ttest gpa, by(sexstud) . Note that the outcome variable (or dependent variable) is placed right after the command ttest and there is a "comma" sign after GPA, followed by "by" and the categorical variable in parenthesis.
Download studentdata2008 for your analysis below:
ttest gpa , by (sexstud)

The first thing you are looking into at the above figure table is the mean values of female and male. It is clear that female scored higher on their GPA (6.58) compared to male of 5.68. Second, the probability value which in this case the middle one (the two-tailed test**see the notes below: for more information on this, this link to UCLA website is helpful). You are looking at a p value of less than 0.05 so that you can make a conclusion that there is a significant relationship between gender and GPA, specifically, to say that female is more likely to perform better than male. The circle #3 is used for your report write up. There are many ways you can write this up in your paper for your class or publication, but this is what I would write:
"This study seeks to examine the difference between academic performance by students' gender. The results based on an independent group t-test show that female students (M=6.58, SD=.13) tend to perform better than their male counterparts (M=5.68, SD=.14), t(268)=4.67, p<.001."
Note that whenever you report mean, you need to also report standard deviation.
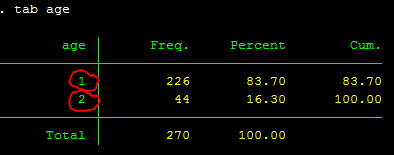
As you recall, last week we also use the command tab/sum to find the mean difference between two groups and it would give the same results to the ttest command. However, the tab/sum command does not give you statistical significance. So for example, if you run tab (sexstud), sum (gpa), you get the following:
tab (sexstud), sum (gpa)

You can see that the tab/sum command above gives you the same mean/sd results, but no statistical significance, and that's when t-test becomes useful.
So now how do you build a table that you can put it in your paper or report? You cannot copy and paste the ttest table above directly to your paper. Here it is a sample that I created for your reference:

If you have more than one variables, you can put them in after the academic performance, but their predictor (or Independent Variable) must be gender, otherwise, you need to create another table for it.
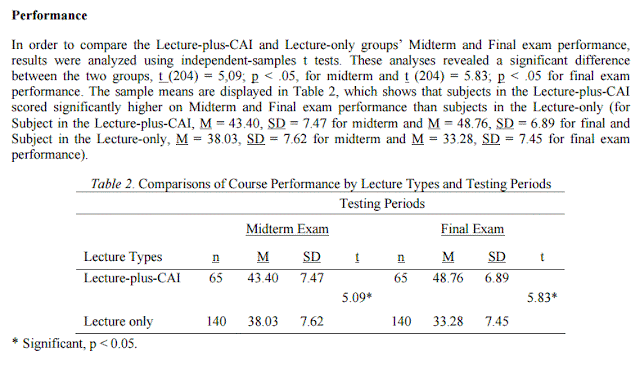
For your real world reference, I included below ttest results from an article published in Educational Technology & Society (pages 170-178) so that you can see the variety of tables are being used. It would be useful later when you become an evaluator of any program.

Paired T-Test
This type of t-test seeks to answer relationship between two continuous variables that are not independent of one another, meaning that the same participants responded to the two variables at one point or two different times. For example, in my study, I compared involvement by mother and by father as reported by the student. So I have two measures: mother involvement and father involvement. I want to see the average scores of these two measures--which one scores higher? My hypothesis is that mother would have higher level of involvement than father. The command for this test is ttest involvemother==involvefather
Download studentdata2013 for your analysis below:
ttest involvemother==involvefather

Based on the above table, you can see that mother scored higher in their involvement with their children (M=2.52, SD=.67) compared to that of father (M=2.46, SD=.73), t(853)=3.37, p<.001.
Now it is your turn to practice your write up based on these above results as well as your APA styled table.
Paired-ttest is also commonly used for comparing scores from two different times, pre-test and post-test that are obtained from the same participants. Look at this report that my colleague, Dr. Scott Plunkett, Professor of Psychology at Cal State, Northridge and I wrote as part of an evaluation for Western Justice Center Foundation located in California, and how the results are reported and how the table is built (link to the report).

and this one:

and here is an excerpt taken from Executive Summary part of the report showing how the results were reported:

Practice on Your Own
1. Using studentdata2013 data, please compare each involvement score between father and mother. In other words, is involvemom1 different from involvedad1 and so forth for the ten of them. Which one is significant?
2. Using studentdata2013 data, is there a difference between education of mother (edumom) in academic performance (rank) of their children?
3. Using studentdata2013 data, does education of father matter in their children's academic performance (rank)?
4. Using studentdata2013 data, does having electricity at home (electricity) improve students' academic performance (rank)?
5. Using studentdata2013 data, does mother involvement improve academic performance (rank) of their children?
6. Using studentdata2013 data, does father involvement improve academic performance (rank) of their children?
7. Please do not simply paste your outputs, but also add your answer in writing as well.
Note: **, one-tailed test tests just one direction of a relationship; whereas two-tailed test tests both directions (your p-value will need to be divided by two). One-tailed test is more powerful than a two-tailed test, because one-tailed test does not need to be divided--it's just a test for one direction. If you know the direction of your relationship (e.g., females perform better than males), then use a one-tailed test. If you do not know the direction, then use the two-tailed test. If you use a two-tailed test, and want to get a one-tailed result, then just divide the p-value of the two-tailed p-value by 2. In your ttest gpa, by(sexstud) above, your two-tailed test p-value is 0.0000 (the one in the middle). If you divide it by 2, it is still 0.0000 (the one on the right side). To get another one in the left side, you use 1-.0000, and it's 1.0000. To keep it simple, we will just use a two-tailed p-value throughout the class. Also note that usually a two-tailed test is shown by default in any statistical outputs.
Independent Group T-Test
Research questions for this type of test may include: (1) are there any income differences between male and female employees? (2) Is GPA different by gender? (3) compared to those who have studied abroad, do those who have not earn more salary? (4) do people who went to a private university earn better salary compared to those who went to a public university? etc. Remember that t-test allows only two groups (e.g., male or female; study abroad vs. not study abroad). If you have a variable that has three or more groups (e.g., ethnicity or type of car etc.), then ANOVA (Oneway Analysis of Variance) is appropriate. We will cover this later. Let's look at our studentdata2008 data and try to run a few t-tests. First let's see if there is any difference in GPA between male and female students. The command for it is: ttest gpa, by(sexstud) . Note that the outcome variable (or dependent variable) is placed right after the command ttest and there is a "comma" sign after GPA, followed by "by" and the categorical variable in parenthesis.
Download studentdata2008 for your analysis below:
ttest gpa , by (sexstud)
The first thing you are looking into at the above figure table is the mean values of female and male. It is clear that female scored higher on their GPA (6.58) compared to male of 5.68. Second, the probability value which in this case the middle one (the two-tailed test**see the notes below: for more information on this, this link to UCLA website is helpful). You are looking at a p value of less than 0.05 so that you can make a conclusion that there is a significant relationship between gender and GPA, specifically, to say that female is more likely to perform better than male. The circle #3 is used for your report write up. There are many ways you can write this up in your paper for your class or publication, but this is what I would write:
"This study seeks to examine the difference between academic performance by students' gender. The results based on an independent group t-test show that female students (M=6.58, SD=.13) tend to perform better than their male counterparts (M=5.68, SD=.14), t(268)=4.67, p<.001."
Note that whenever you report mean, you need to also report standard deviation.
As you recall, last week we also use the command tab/sum to find the mean difference between two groups and it would give the same results to the ttest command. However, the tab/sum command does not give you statistical significance. So for example, if you run tab (sexstud), sum (gpa), you get the following:
tab (sexstud), sum (gpa)
You can see that the tab/sum command above gives you the same mean/sd results, but no statistical significance, and that's when t-test becomes useful.
So now how do you build a table that you can put it in your paper or report? You cannot copy and paste the ttest table above directly to your paper. Here it is a sample that I created for your reference:
If you have more than one variables, you can put them in after the academic performance, but their predictor (or Independent Variable) must be gender, otherwise, you need to create another table for it.
For your real world reference, I included below ttest results from an article published in Educational Technology & Society (pages 170-178) so that you can see the variety of tables are being used. It would be useful later when you become an evaluator of any program.


Paired T-Test
This type of t-test seeks to answer relationship between two continuous variables that are not independent of one another, meaning that the same participants responded to the two variables at one point or two different times. For example, in my study, I compared involvement by mother and by father as reported by the student. So I have two measures: mother involvement and father involvement. I want to see the average scores of these two measures--which one scores higher? My hypothesis is that mother would have higher level of involvement than father. The command for this test is ttest involvemother==involvefather
Download studentdata2013 for your analysis below:
ttest involvemother==involvefather
Based on the above table, you can see that mother scored higher in their involvement with their children (M=2.52, SD=.67) compared to that of father (M=2.46, SD=.73), t(853)=3.37, p<.001.
Now it is your turn to practice your write up based on these above results as well as your APA styled table.
Paired-ttest is also commonly used for comparing scores from two different times, pre-test and post-test that are obtained from the same participants. Look at this report that my colleague, Dr. Scott Plunkett, Professor of Psychology at Cal State, Northridge and I wrote as part of an evaluation for Western Justice Center Foundation located in California, and how the results are reported and how the table is built (link to the report).
and this one:
and here is an excerpt taken from Executive Summary part of the report showing how the results were reported:
Practice on Your Own
1. Using studentdata2013 data, please compare each involvement score between father and mother. In other words, is involvemom1 different from involvedad1 and so forth for the ten of them. Which one is significant?
2. Using studentdata2013 data, is there a difference between education of mother (edumom) in academic performance (rank) of their children?
3. Using studentdata2013 data, does education of father matter in their children's academic performance (rank)?
4. Using studentdata2013 data, does having electricity at home (electricity) improve students' academic performance (rank)?
5. Using studentdata2013 data, does mother involvement improve academic performance (rank) of their children?
6. Using studentdata2013 data, does father involvement improve academic performance (rank) of their children?
7. Please do not simply paste your outputs, but also add your answer in writing as well.
Note: **, one-tailed test tests just one direction of a relationship; whereas two-tailed test tests both directions (your p-value will need to be divided by two). One-tailed test is more powerful than a two-tailed test, because one-tailed test does not need to be divided--it's just a test for one direction. If you know the direction of your relationship (e.g., females perform better than males), then use a one-tailed test. If you do not know the direction, then use the two-tailed test. If you use a two-tailed test, and want to get a one-tailed result, then just divide the p-value of the two-tailed p-value by 2. In your ttest gpa, by(sexstud) above, your two-tailed test p-value is 0.0000 (the one in the middle). If you divide it by 2, it is still 0.0000 (the one on the right side). To get another one in the left side, you use 1-.0000, and it's 1.0000. To keep it simple, we will just use a two-tailed p-value throughout the class. Also note that usually a two-tailed test is shown by default in any statistical outputs.